
mybatis使用load data local infile实现导入数据到my



温馨提示:这篇文章已超过598天没有更新,请注意相关的内容是否还可用!
背景:

项目框架为:dubbo+zookeeper+ssm 数据库为mysql
最近有一个新需求,在代码中向数据库中插入大量数据。 每次插入的数据量在10万到50万条之间,每条数据有80多个字段。 我粗略估计,一条数据的大小在1kb左右,所以每次插入的数据大小应该在100M到500M之间。 数据量还是很大的。
想来想去,还是按照从开发到调试遇到的问题的顺序来写,后面再把代码贴出来mssql 数据库导入,供同行们参考。
1.遇到的第一个问题是:
查询数据包过大(1139736>1048576)。 您可以通过设置在服务器上更改此值
'max_allowed_packet' 变量。
刚开始接到需求的时候,完全没有考虑数据量。 我照例直接执行insert到数据库,报了上面的错误。 原来mysql有一个max_allowed_packet变量,可以控制它的通信缓冲区的大小。 最大长度,所以当缓冲区的大小太小时,一些查询和插入操作会报错。
解决方案:
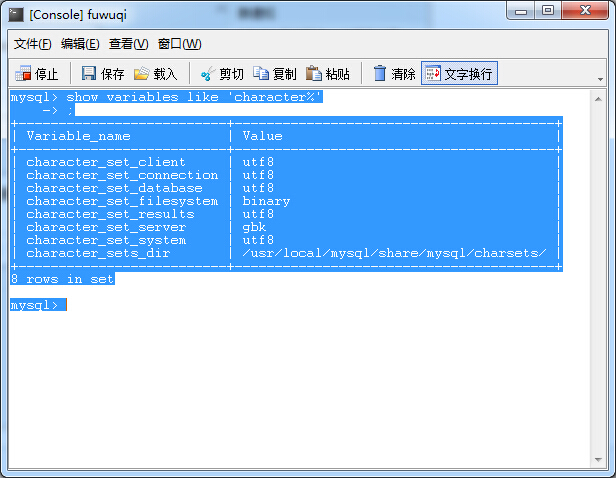
数据库执行命令 show VARIABLES like '%max_allowed_packet%'; 查看数据库max_allowed_packet变量配置,显示结果为
+--------------------+--------+ | 变量名 | 价值 | +--------
----------+--------+ | 最大允许数据包 | 1048576 | +--------------------+---------+
这表明当前配置为1M,我们需要将其设置大一些。
数据库执行命令set global max_allowed_packet = 4*1024*1024*10,设置值为40M。 执行完后,关闭数据库可视化界面,再重新打开。 如果命令行执行,重启mysql(不重启是不行的,记得重启mysql),然后执行命令show VARIABLES like '%max_allowed_packet%'; 查看是否设置成功。 一般有效! 至此,第一个问题就解决了。
2.遇到的第二个问题是:
com.alibaba.dubbo.remoting.transport.AbstractCodec.checkPayload() 错误数据长度太大:11557050,最大有效载荷:8388608 java.io.IOException:数据长度太大:11557050,最大有效载荷:838860
这个错误和dubbo有关,为什么会报这个错误? 想来想去,可能是服务端读取的数据量太大,服务端给web客户端提供的数据量太大,超过了dubbo默认的8M。 错误信息如上所示。 我的天,第一次遇到这样的报错,查了各种资料mssql 数据库导入,终于解决了。
解决方案:
方法一、修改provider的dubbo配置,
在 dubbo.properties 添加如下内容
dubbo.protocol.dubbo.payload=41943040(默认8M,即8388608)
方法二,
dubbo-provider.xml文件中的配置如下
以上两种方法都是将值修改为40M。
3.遇到的第三个问题:
使用mysql的load data local infile向数据库导入数据时,英文和数字都正常导入,但是汉字要么不显示,要么是乱码。 我真的不明白。 怎么会这样呢? 以下是代码的导入部分:
[java] 查看普通副本
public void batchInsert(List bqLoanList) throws ClassNotFoundException, SQLException { //1000 项提交一次 int COMMIT_SIZE=1000; //一共多少条 int COUNT=bqLoanList. 尺寸(); 连接conn = null; 尝试 { 类。 forName("com.mysql.jdbc.Driver"); 字符串 url = GetResourceFromProperties。 GetResourceFromPropertiesFromfiles("/jdbc.properties","jdbc.url","CONF_HOME"); 字符串用户 = GetResourceFromProperties。 GetResourceFromPropertiesFromfiles("/jdbc.properties","jdbc.username","CONF_HOME"); 字符串密码 = GetResourceFromProperties。
GetResourceFromPropertiesFromfiles("/jdbc.properties","jdbc.password","CONF_HOME"); conn = 驱动程序管理器。 getConnection(网址,用户,密码); 康涅狄格州设置自动提交(假); String executeSql = "load data local infile '' into table bq_loan fields terminated by ','"; PreparedStatement pstmt = conn. 准备语句(execututeSql); StringBuilder sb = new StringBuilder(); 对于 (int i = 0; i < COUNT; i++) { sb. append(getTestDataInputStream(bqLoanList.get(i))); if (i % COMMIT_SIZE == 0) { InputStream is = null; 尝试 { is = new ByteArrayInputStream(sb.
到字符串()。 得到字节()); ((com.mysql.jdbc.Statement)pstmt)。 setLocalInfileInputStream(是); pstmt。 执行(); 康涅狄格州犯罪(); 某人。 设置长度(0); } catch (UnsupportedEncodingException e) { e. 打印堆栈跟踪(); } } } InputStream = null; try { is = new ByteArrayInputStream(sb.toString().getBytes()); ((com.mysql.jdbc.Statement)pstmt)。 setLocalInfileInputStream(是); pstmt。 执行(); 康涅狄格州犯罪(); } catch (UnsupportedEncodingException e) { e. 打印堆栈跟踪(); } } catch (SQLException e) { e. 打印堆栈跟踪(); }最后{康恩。 关(); } } }
上面的代码是导入零件的方法。 怎么导入都不显示中文,有些字段中文乱码。 我想一定是字符集的问题。 首先,检查数据库字符集。 (查询命令为:show variables like '%char%';),然后看代码,查询结果显示数据库字符集为utf8,然后百度发现导入代码必须加上编码格式:
[java] 查看普通副本
“将数据本地 infile '' 加载到以 ',' 结尾的表 bq_loan 字段中”;
这个加上红色部分的编码格式设置如下,
“将数据本地 infile '' 加载到表 bq_loan 字符集 utf8 字段中,以 ',' 结尾”;
修改后再次导入,还是老样子,不显示中文,有的字段中文乱码,很头疼。 仔细查看,加了各种百度,发现代码挖坑了。
[java] 查看普通副本
is = new ByteArrayInputStream(sb.toString().getBytes());
将字节数组转换为输入流时,将字符串转换为括号内的字节数组时,并没有给出转换后的字节数组的编码格式,所以使用默认的编码格式。 我们知道,不同的编码格式,单个中文和英文对应的字节数是不同的。 所以我猜测是这个地方没有设置好,导致生成的字节数组的编码格式和数据库的编码格式不一致,最终导致导入数据的时候不能显示中文,出现乱码。 然后在getBytes()方法中加入编码格式,代码如下。
[java] 查看普通副本
is = new ByteArrayInputStream(sb.toString().getBytes("UTF-8"));
添加之后,导入数据,一切顺利,数据导入库没有任何错误。
至此,衍生已经顺利进行,但是想到以后业务发展壮大的时候,dubbo服务端为消费者提供最大的数据量是不够的,所以决定改一下代码,最后和同事讨论。 推荐采用 批量插入是在调用业务服务器时进行分页处理。 每页的数据量设置在dubbo允许服务器向消费者提供最大数据量的范围内,然后每次插入数据时,都会批量插入。 只是和数据库的交互次数比较多,影响不大。
还有一个。 在使用“load data local infile”导入数据时,我直接将查询结果(列表集合)和数据结合起来,即用“,”分隔每条数据的各个字段,每条数据之间用"/n"换行,最后将每条数据拼接成字符串,然后将字符串转成字节数组转成输入流,再进行导入操作,然后就是相对简单起来。 由于我不通过文件进行派生操作,所以我不会将load data local infile ''中红色部分的文件名和地址写入表bq_loan字符集utf8字段以','结尾"。
最终结果是:
导入10000条数据大约需要5.5秒
导入26000条数据大约需要17.8秒
……
导入35万条数据,耗时约210秒
导入50万条数据大约需要305秒
我的每条数据量都比较大,1条1kb左右,感觉速度还不错,能满足我的需求。
好了,下面贴出部分代码供大家参考。
[java] 查看普通副本
public void insertLoanInfo (Map msg) { try { long startTime = DateOperation.currentTimeMills(); 列出 loanList = (List)msg.get("loanList"); String pkgName = (String) msg.get("pkgName"); String pkgCde = (String) msg.get("pkgCde"); // 备份时间 String bkTime = DateOperation.convertToDateStr1(DateOperation.currentTimeMills()); msg.put("bkTime",bkTime); 如果 (IS_ONE_KEY_ASSOCIATED.getCode() .equals(msg.get("isOneKeyAssociated"))) { BqLoanService.deleteByPkgCde(pkgCde); } 列表 bkList = BqLoanService.selectNumByLoanNo(loanList); // 总页数 double totalPage = Math.ceil(bkList.size() /25000.0); 映射 map = new HashMap(); map.put("贷款列表",贷款列表); 列表列表=空; 对于 (int i = 1;i







